Mean Collapse is a Serious Bottleneck of VLA

TL;DR
On OGBench Ant-Maze we train a VLM-based VLA (Qwen3-VL 2B + LoRA, OpenVLA-OFT style) under two cameras and two heads — top-view (MDP) coordinate-VQA and 3rd-person (POMDP) direct action. Both mean-collapse, but the bare top-view collapses to 0%: the ant tips over, twitches, freezes.
The cause specific to VLM-based VLAs is ViT-level feature aliasing — the ant covers a few pixels in top-view, ViT patches are nearly constant across the episode, the LLM sees the same input every step. Higher-resolution top-view fixes it. The coordinate-VQA reformulation also works: top-view recovers to 0.53.
A small memory-based steering module (GLA Linear-SSM + Perceiver) on the frozen 3rd-person VLA lifts success from 0.16 → 0.84 — close to the 0.91 we get with both cameras + VQA, even though steering uses only the 3rd-person input that would be available in the real world. The same Markovian-on-$o_t$ failure shows up on a GUI agent (GELab-Zero) looping C → D → E → C → D → E → … on a Duolingo quiz.
1. MDP vs. POMDP — and Why Mean Collapse Happens
An MDP gives the agent the state directly: $\pi^{\star}_{\mathrm{MDP}}(a_t \mid s_t)$. A POMDP only gives observations $o_t \sim \Omega(\cdot \mid s_t)$, so the optimal policy must condition on history $h_t = (o_0, a_0, \ldots, o_t)$:
$$\pi^{\star}_{\mathrm{POMDP}}(a_t \mid h_t).$$
1.1 Why Mean Collapse Happens
A VLM-based VLA trained to act on the latest observation only learns $\pi(a_t \mid o_t)$. When several states alias to similar observations ($s^{(1)} \neq s^{(2)}$ but $o^{(1)} \approx o^{(2)} \approx o$), the loss is minimized by the posterior-weighted average:
$$ \pi^{\star}(a \mid o) \;=\; \sum_{i} p\!\left(s^{(i)} \mid o\right)\, \pi^{\star}\!\left(a \mid s^{(i)}\right). $$
When per-state optima point in opposite directions, the average is a degenerate output: a near-zero motion, a sideways drift, an oscillation. That is mean collapse — and on Ant-Maze it appears even on the privileged top-view input (Section 6).
2. Most VLA Benchmarks Hide the POMDP
LIBERO, SIMPLER, UI-TARS all assume $\pi(a_t \mid o_t)$ suffices — the current scene already encodes the task-relevant state. Real long-horizon tasks (Minecraft, GUI agents, occluded manipulation) need history $h_t$. Crafting a pickaxe needs “I already chopped a tree”, which is not in the current screen.
3. A Controllable POMDP in OGBench Ant-Maze
We re-render OGBench Ant-Maze in MuJoCo with two cameras — the only thing that differs across our settings is observability:
- Top-view (MDP). $o_t = s_t$ — full layout in one bird's-eye image.
- 3rd-person (POMDP). $o_t \sim \Omega(\cdot \mid s_t)$ — only what is in front of the ant.
 Same world, two views. Left: top-view (MDP). Right: 3rd-person (POMDP).
Same world, two views. Left: top-view (MDP). Right: 3rd-person (POMDP).
4. Setup
4.1 Data
- OGBench
antmaze-{medium,large,giant}-navigate-v0re-rendered through MuJoCo. - $3$ mazes $\times$ $1{,}000$ episodes $\times \sim 1{,}001$ steps, $224 \times 224 \times 3$, two cameras.
- $8$-DOF torque, qpos $15$-D, qvel $14$-D.
- Hindsight relabeling: chunk $K = 16$, terminal-goal fraction $0.25$.
4.2 Two heads, one backbone
Both settings share Qwen3-VL 2B with LoRA on ViT and the LLM head, trained OpenVLA-OFT-style. They differ only in observability and the output head:
- Top-view (MDP) — coordinate VQA. Image + Go to (x, y) $\rightarrow$ waypoint coordinates $(x_1, y_1), \ldots, (x_K, y_K)$ as text. A small low-level controller turns waypoints into 8-DOF torques.
- 3rd-person (POMDP) — direct action. Image + same instruction $\rightarrow$ a parallel-decoded action chunk in joint-torque space.
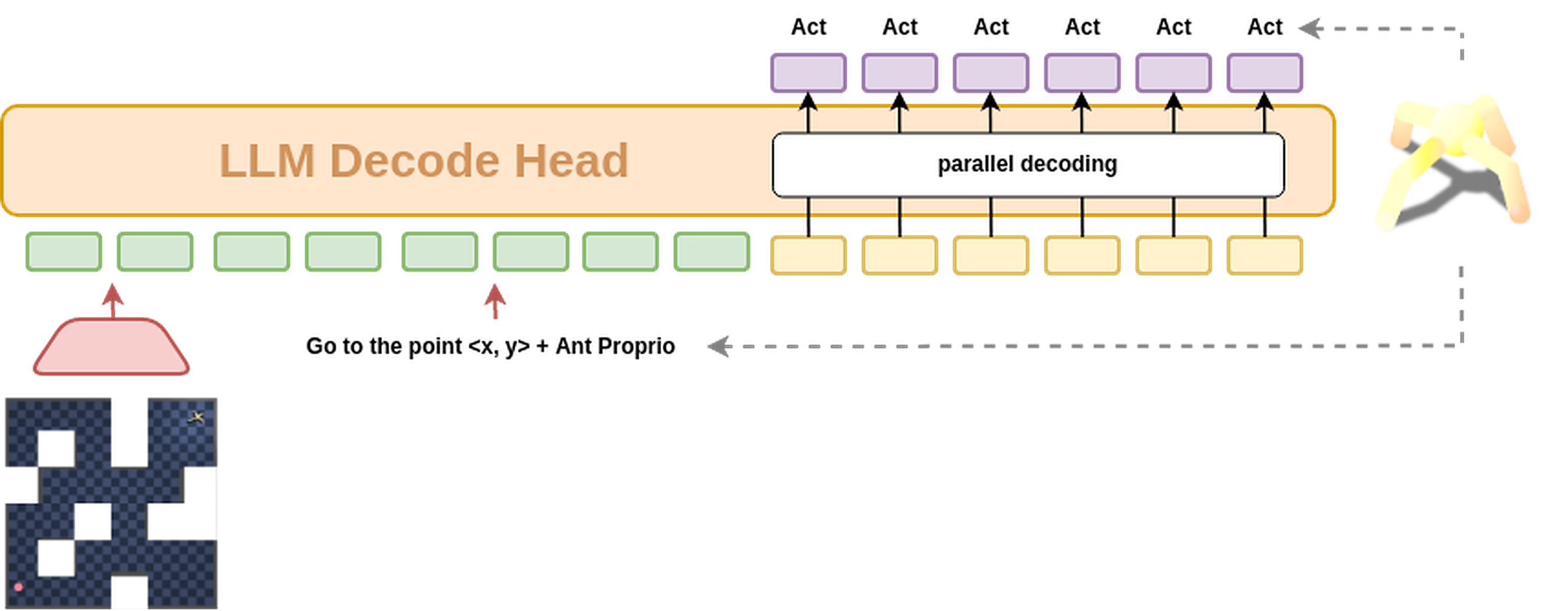 One backbone, two output heads (top-view waypoints vs. 3rd-person action chunk).
One backbone, two output heads (top-view waypoints vs. 3rd-person action chunk).
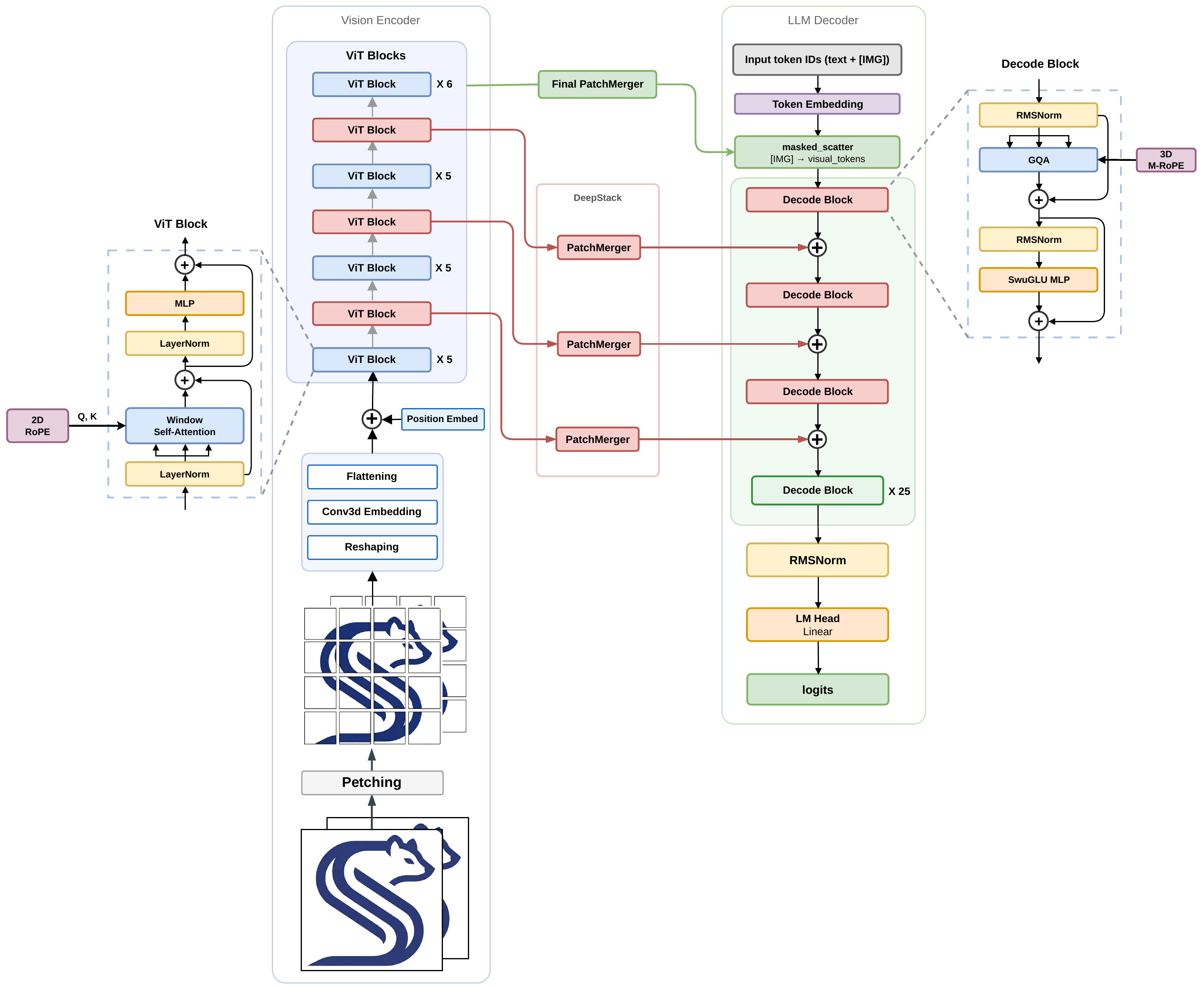 Qwen3-VL 2B backbone — vision encoder (ViT) feeding into the LLM decoder.
LoRA adapters sit on the ViT and the LLM head; everything else stays frozen
at the OpenVLA-OFT level.
Qwen3-VL 2B backbone — vision encoder (ViT) feeding into the LLM decoder.
LoRA adapters sit on the ViT and the LLM head; everything else stays frozen
at the OpenVLA-OFT level.
5. Both Views Mean-Collapse — Bare Top-View Collapses to 0%
The bare top-view + direct-action setting collapses to 0%: the ant tips, twitches, freezes. Only the coordinate-VQA reformulation rescues top-view (see Section 7.3 for the numbers). The 3rd-person rollouts also collapse, but the agent moves more — sometimes winning by exploration when the goal comes into view.
5.1 Top-view (MDP) — different loop-case examples
5.2 Top-view — extreme stuck case
5.3 3rd-person (POMDP) — opportunistic successes
6. Why the Top-View Collapse is Worse — ViT-Level Feature Aliasing
Classical mean collapse (Section 1.1) is about state aliasing in the pixel space. On the top-view that should not apply — the state is fully visible. Yet the bare top-view collapses to 0%. The aliasing happens one level up, in the ViT feature space:
- Tiny scene-relevant region. The ant + goal cover only a few pixels; each $14 \times 14$ ViT patch sees mostly empty maze floor.
- Near-constant patch tokens across the episode. The maze layout is fixed and only a handful of pixels carry the state, so the ViT features barely change between timesteps. The LLM sees almost the same input every step.
- Broad posterior $p(s \mid \phi(o))$ over states given features $\rightarrow$ the mean-collapse identity drives the output toward a near-zero average.
- 3rd-person is the opposite — patches are filled with scene content, features change clearly between observations, and there is enough signal to commit to a direction.
6.1 Sanity check — higher-resolution top-view fixes it
If feature aliasing is really the cause, more pixels per scene should sharpen the features and reduce collapse. Confirmed: feeding higher-resolution top-view images into the ViT (same backbone, same head, same prompt) recovers performance. When a VLM-based VLA mean-collapses on a supposedly-MDP input, suspect resolution / feature aliasing first.
7. The Fix — A Memory-Based Steering Module on the Frozen VLA
 Learnable steering (peach) builds a fixed-size memory $Z$ from past ViT
features via a GLA temporal mixer + Perceiver compression, then injects
it into the frozen ViT at L8 / L16 and the action head through gated
residuals. The frozen base VLA (green) is never re-trained.
Learnable steering (peach) builds a fixed-size memory $Z$ from past ViT
features via a GLA temporal mixer + Perceiver compression, then injects
it into the frozen ViT at L8 / L16 and the action head through gated
residuals. The frozen base VLA (green) is never re-trained.
7.1 Formulation
Past ViT features $h^{(\ell)}_{t-k}$ at depths $\ell \in \{8, 16\}$ for $k = 1, \ldots, K$ are mixed by a Gated Linear Attention (Linear SSM) with content-gated decay:
$$ \begin{aligned} S_k &= \sigma(g_k) \odot S_{k-1} + K_k^{\top} V_k, \\ O_k &= Q_k\, S_k. \end{aligned} $$
The mixed sequence is compressed to $m = 32$ memory tokens by a Perceiver cross-attention with learnable queries $Q_{\text{learn}} \in \mathbb{R}^{m \times d}$:
$$ Z^{(\ell)} \;=\; \mathrm{CrossAttn}\!\left(Q_{\text{learn}},\; O^{(\ell)}_{1:K}\right). $$
Memory is injected back into the frozen ViT through gated residuals, and a small residual is added to the frozen action head:
$$ \tilde{h}^{(\ell)}_t = h^{(\ell)}_t + \sigma(\alpha_\ell)\, \mathrm{CrossAttn}\!\left(h^{(\ell)}_t, Z^{(\ell)}\right), \qquad a_t = \underbrace{\pi_{\text{base}}(o_t)}_{\text{frozen}} + \sigma(\alpha_{\text{res}})\, \Delta\!\left(Z^{(16)}\right). $$
Identity-init gates ($\sigma(\alpha) = 0$) make the module a no-op at initialization — the base VLA is recovered exactly, only corrections are learned.
7.2 Why a State-Space Model?
- Long sequence. $T = K \cdot N_{\text{patch}} \sim 2{,}000$ tokens; $\mathcal{O}(T)$ vs. quadratic attention.
- Content-gated decay. $\sigma(g_t)$ — per-token forget; more expressive than a fixed $\gamma$, more stable than plain linear attention.
- Length extrapolation. Train with $K \sim \mathcal{U}[1, 32]$; stable at $K \in \{64, 128\}$ at inference.
- Identity-init $\rightarrow$ safe to bolt onto a frozen VLA.
7.3 Results — full picture in one table
| Setting | Camera | Output head | Success rate |
|---|---|---|---|
| Top-view, no VQA | Top-view (MDP) | Direct action chunk | 0.00 |
| Top-view, with VQA | Top-view (MDP) | Coordinate-VQA waypoints | 0.53 |
| 3rd-person, baseline | 3rd-person (POMDP) | Direct action chunk | 0.16 |
| 3rd-person, with steering | 3rd-person (POMDP) | Direct action + steering module | 0.84 |
| Top-view + 3rd-person, with VQA | Both cameras | Coordinate-VQA waypoints | 0.91 |
7.4 Reading the table
The top number — 0.91 with both cameras + VQA — is what we got when the top-view (MDP layout) is paired with the 3rd-person view (scene-rich, high-res ViT-friendly content). Our reading: top-view supplies the MDP state, and 3rd-person supplies the kind of high-resolution patch features the ViT needs to avoid feature aliasing — the two views compensate for each other's failure modes.
The surprising part is how close the 3rd-person + steering module number (0.84) gets to the privileged-top-view 0.91. This matters because in the real world a top-view is almost never available; steering on the frozen 3rd-person VLA is the practically meaningful intervention, and the fact that the gap to a setup with the bird's-eye state is so small is the encouraging signal.
On where the remaining failures come from: most of them are not mean-collapse anymore. They are locomotion failures — the ant moves quickly mid-trajectory and tips over, after which the simulation marks the episode as failed. The mean-collapse pathology has largely been removed; what is left is a controller/dynamics issue rather than the VLA itself.
8. Bonus — Same Pathology on a GUI Agent
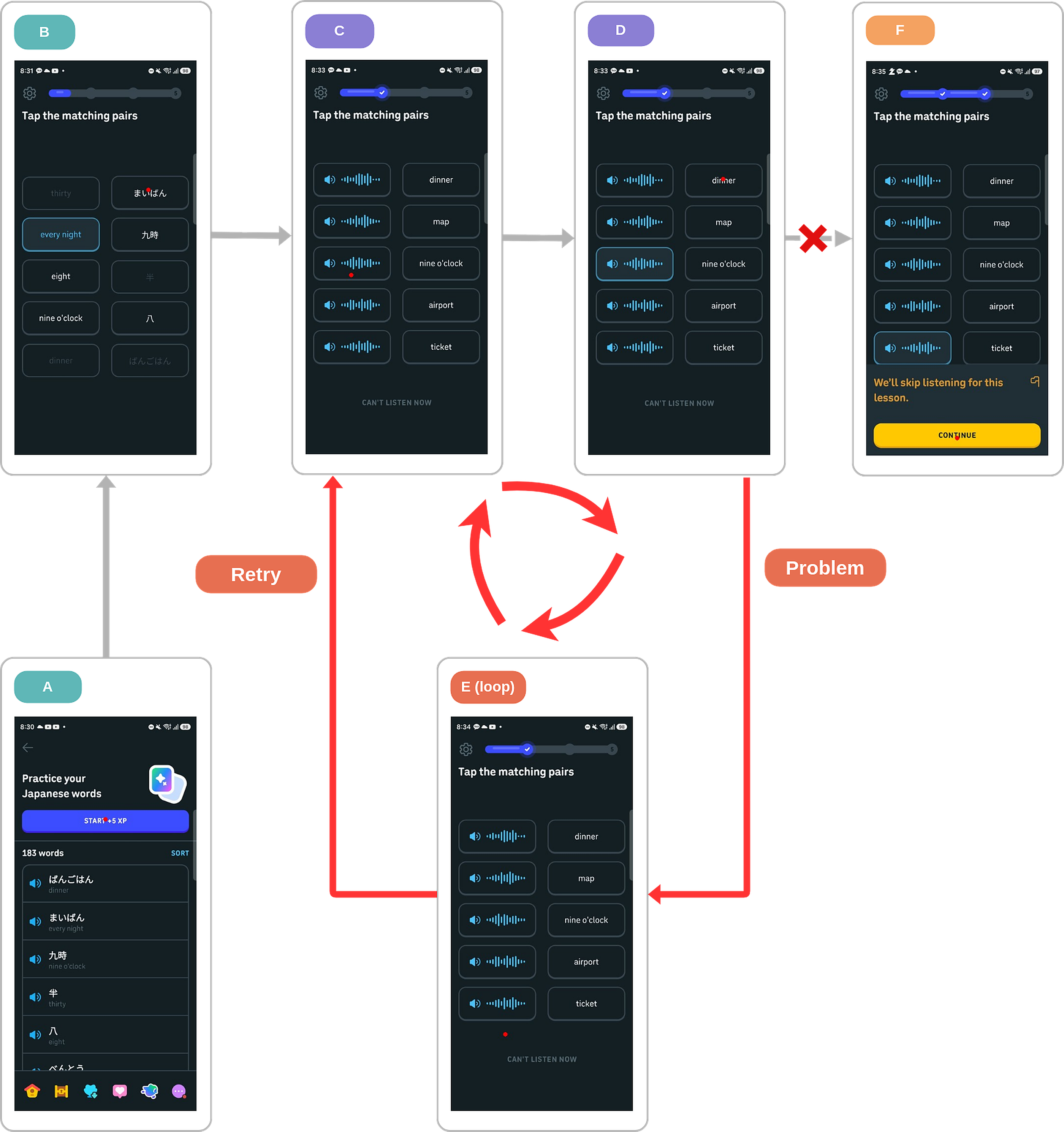
The same Markovian-on-$o_t$ failure shows up on a real GUI agent. GELab-Zero-4B-preview on a Duolingo “tap the matching pairs” quiz: solved tiles look almost identical to fresh ones, the agent has no memory of what it has tapped, so it re-taps a solved pair and the screen returns to the same state — a three-step loop:
$$C \rightarrow D \rightarrow E \rightarrow C \rightarrow D \rightarrow E \rightarrow \ldots$$
 GELab-Zero-4B-preview on the Duolingo quiz —
each step it sees only the current screenshot.
GELab-Zero-4B-preview on the Duolingo quiz —
each step it sees only the current screenshot.
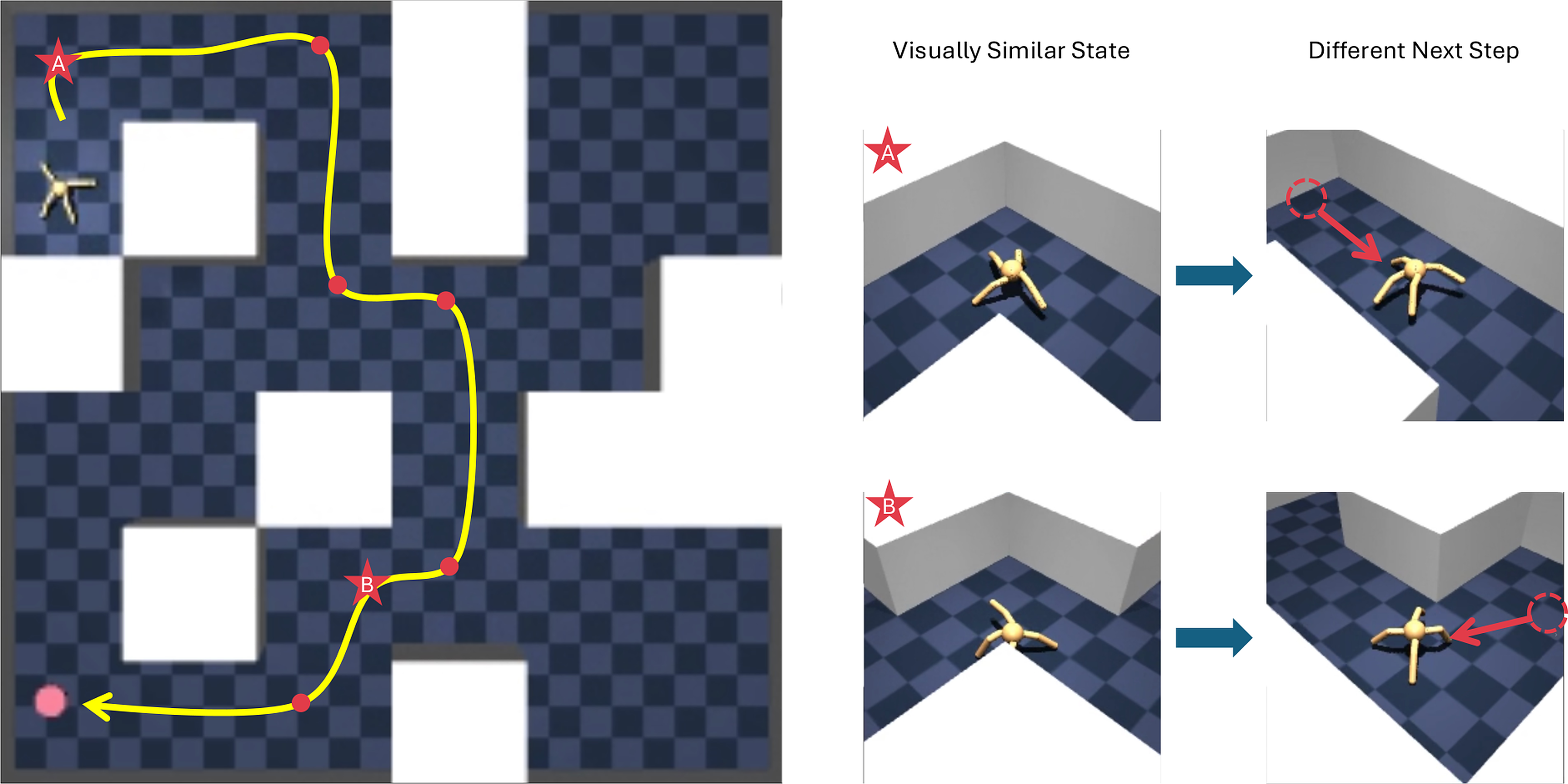
 Loop-case definition: $o_t$ (screenshot) $\not\Rightarrow s_t$ (solved-set).
Loop-case definition: $o_t$ (screenshot) $\not\Rightarrow s_t$ (solved-set).
9. Takeaway
- Mean collapse is the bottleneck for VLM-based VLAs on the latest observation. The optimal Markovian policy is the posterior-weighted average of per-state optima — degenerate when those disagree.
- The privileged top-view does not save you. Bare top-view + direct-action collapses to 0%; the cause is ViT-level feature aliasing, fixed by higher-resolution input or by reformulating the task as coordinate VQA (0.53).
- A small memory-based steering module on the frozen 3rd-person VLA raises success from 0.16 → 0.84 — close to the 0.91 we get with both cameras + VQA, even though the top-view is unavailable in the real world. Most remaining failures are locomotion-level falls, not mean collapse.
- Same pathology beyond robotics — a frozen GUI agent loops C → D → E → … on a Duolingo quiz for the same reason.
References
- Qwen3-VL — arxiv.org/abs/2511.21631
- OpenVLA-OFT — openvla-oft.github.io
- GELab-Zero — github.com/stepfun-ai/gelab-zero
- OGBench — seohong.me/projects/ogbench
Acknowledgement

This research was made possible by the TPU Research Cloud (TRC) program. We are grateful to the TRC Team and Google for providing the TPU compute that made these experiments feasible.
Sub-project of Project Weasel, maintained by Kang Minkyu.